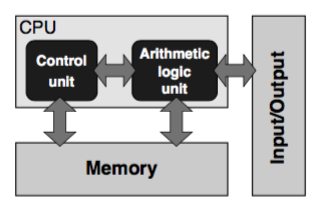
The stored-program computer architecture was first proposed by Von Neumann in 1946, it basically consists on a Control Unit to control access to the memory; an Arithmetic control unit which make all the calculations (ALU); a memory to store data necessary for the calculations and instructions and an Input/Output usually known as I/O.[Hager][1]
To program this processors is necessary to use assembly code. That would let the processor execute some desired operation. For instance, if you would like to perform $a +b = c$ the instruction you should give is:
load a $1
load b $2
load c $3
add $1 $2 $3
save $3
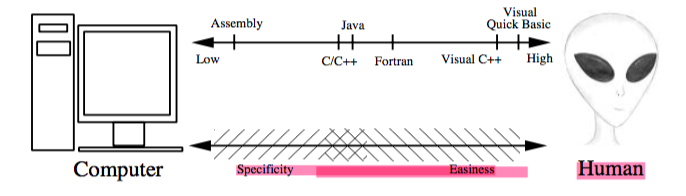
Fortunatelly, we have compilers that let us focus on the program rather than the syntax. There are only very few situations where knowing assembly code would provide some benefit in computational time for solving a problem. For this reason this wont be the matter of study here. As a side note, the closer the programming languaje is to the machine the lower its level is, and the closer it be for the human interaction the higher its level is [karnidabis et.all][2]. As follows:
There are two basic drawnbacks this architecture possess:
-
VonNeumman bottleneck : Given the tremendous ammount of data comming from the memory into the control unit or the arithmetic unit, there exist a limitation in the computing performance.
-
SISD (Single instruction single data) The instructions are inherently sequential, processing a single instruction with a single or a group operands from memory.
Cache Based Processors
Knowing that accessing main memory is expensive. In the recent years, following the architecture described before, processors have been developed with portions of data available at no considerable cost.
Latency: is the delay between the processor issuing a request for a memory item, and the item actually arriving. We can distinguish between various latencies, such as the transfer from memory to cache, cache to register, or summarize them all into the latency between memory and processor. Latency is measured in (nano) seconds, or clock periods.[3]
The so-called memory hierarchy establishes the ammount of data available, the bandwith, and the latency each of such portions have. There is a trade off betweenlatency and bandwith: The lower latency, the higher bandwith. i.e the faster data is available to be proccessed, the lower capacity for storing/loading data. The following picture ilustrates this very clear. [Eijkhout][3]
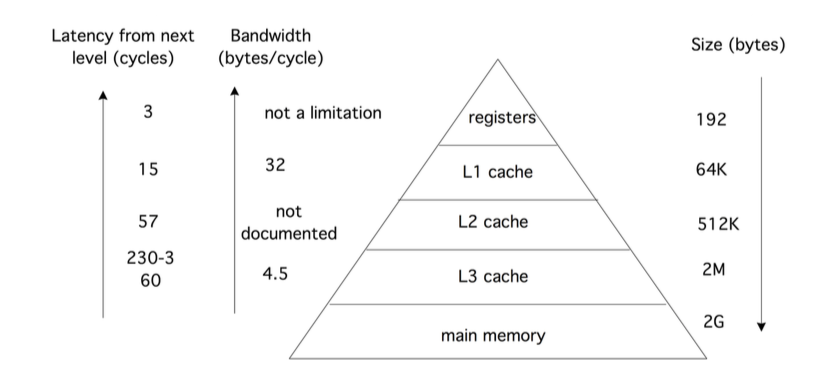
Band-with:is the rate at which data arrives at its destination, after the initial latency is overcome. Band- width is measured in bytes (kilobyes, megabytes, gigabyes) per second or per clock cycle. The bandwidth between two memory levels is usually the product of the cycle speed of the channel (the bus speed ) and width of the bus: the number of bits that can be sent simultaneously in every cycle of the bus clock.[3]
-
Registers: Register are very close to the processor, for this reason loading data from them is very fast, consequently there is no interference at all in an execution speed of an algorithm. Normally processors counts with several registers, they can store either data or instructions, usually by separate.
-
L1 and L2 cache: They can store a considerably but small portions of data and instructions with a high bandwith. They are in charge to back up registers in case they don’t have some instruction loaded already. In case that L1 or L2 cache does not have them either, they would access main memory.
-
Main Memory: It have a large ammount of capacity to store data and instructions, however loading data from it costs up to 100 cycle. For this reason the more can be done with the registers and cache the more effective the computer would run.
Nowadays modern processors are looking to introduce more cores rather than only putting more transistors in each core. The reason is that while techonology for core was increasing fast, memory capacity was low. There are some other features that can be optimized like the use of power and the cooling for processors.
Resources:
These resources would be used in the following posts. I am putting it here because is the first one and I don`t want to get you guys bored repeating same stuff.
[1] Hager,Wellein. Introduction to High Computing Performance for scientist and engineering. CRC press. pages 27-30 2010
[2] George E Karniadakis_ Robert M Kirby-Parallel scientific computing in C++ and MPI _ a seamless approach to parallel algorithms and their implementation-Cambridge university press (2003)
[3] Victor Eijkhout. Introduction to High Performance Scientific Computing. 2011.
[4] F. Deserno, Hager, et. all. Introduction to High Computing Performance. Munich, 2004. Page 10.
[5] Kristoffer, available online : http://kristoffer.vinther.name/academia/thesis/modern_processor_and_memory_technology.pdf
[6]Lecture Notes: Out-of-Order Processors,Rajeev Balasubramonian, Utah, 2007. available online:http://www.eng.utah.edu/~cs6810/ooo.pdf
[7] Wright Maury, Pipeline and out-of-order instruction execution optimize performance, http://renesasrulz.com/doctor_micro/rx_blog/b/weblog/archive/2010/05/17/pipeline-and-out-of-order-instruction-execution-optimize-performance.aspx