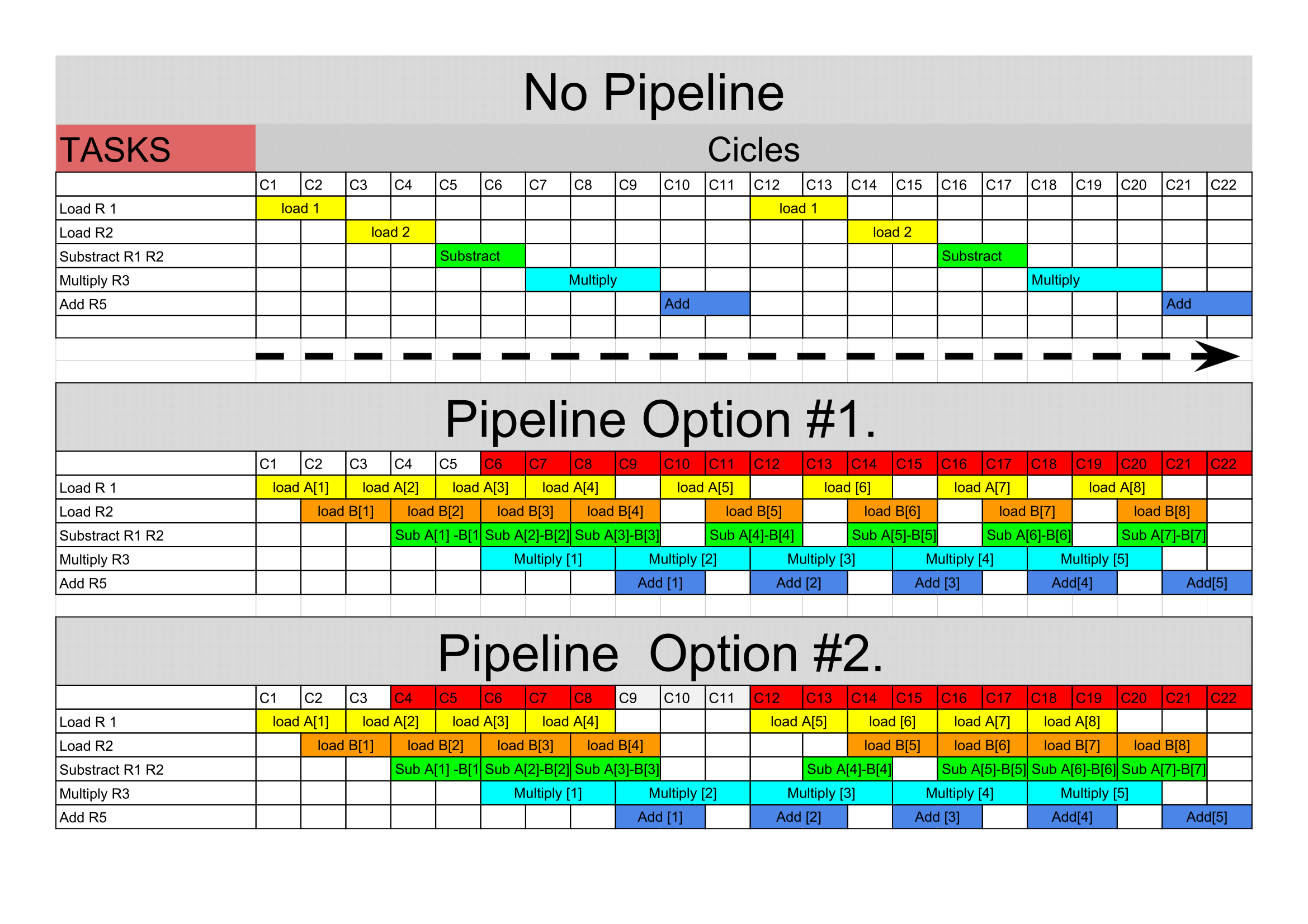
Parallel computing has been the key tool for high performance computing in the last decade. The idea is to brake a long and hard problem into a several smaller ones that can be executed in different cores, solving the problem in a coperative way[hager][1]. However, being able to guarantee that the portion of cached memory is an accurate copy of main memory is known as cache coherence[Eijkhout][2].
Those computers that use the same physical space address for their processors are known as “shared-memory computers”. In this case there are two very different ways to access memory, with the following caracteristics:
-
Uniform Memory Access (UMA): In this case latency and bandwith is the same for all processors and all memory locations.
-
On cache-coherence Nonuniform Memory Acces (ccNUMA): In this case memory is physically distributed but logically shared. i.e.Each processor would process their own portion of memory, but using a network logic makes it a whole system appears as a one single addres space.
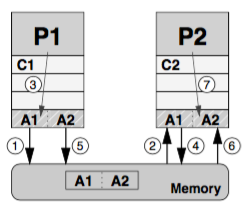
Both of these systems may have multiple CPUs with copies of the same cache line in different caches, probably in modified state. For this reason is necessary to have cache coherence policies that guarantee consistency between cached data and data in memory at all times.
One of the protocols that guarantees the information coherence is the MSI protocol:
- M modified: The cache line has been modified in this cache, and ir resides in no other cache thant this one. Therefore a cache with a block in “M” state is responsable of writing it back to the memory.
- S shared: The cache line has been read from a memory but not (yet) modified. There are read-only copies in at least one other cache. The cache can evict data without writing back
- I invalid: The cache line does not reflect any sensible data. Usually this happens if the cache line was in “S” state but another processor has requested exclusive ownership.
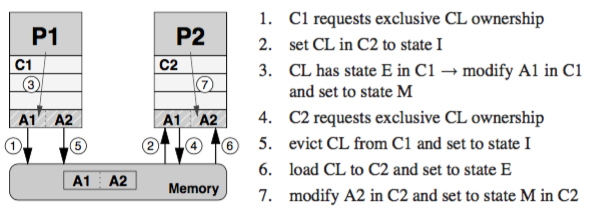
Taken from [1]
Resources:
[1] Hager,Wellein. Introduction to High Computing Performance for scientist and engineering. CRC press. pages 27-30 2010
[2] Victor Eijkhout. Introduction to High Performance Scientific Computing. 2011.
[3] https://en.wikipedia.org/wiki/MSI_protocol

{kind=link}